Anatomy of an agentic AI system: a reference architecture for builders
A long-form walk through the nine layers every production agentic system shares, the tools that won at each layer in 2025 and 2026, and a sober look at what is genuinely new versus what is a relabelled prototype.
By Solomon Udoh · AI Architect & Certification Lead
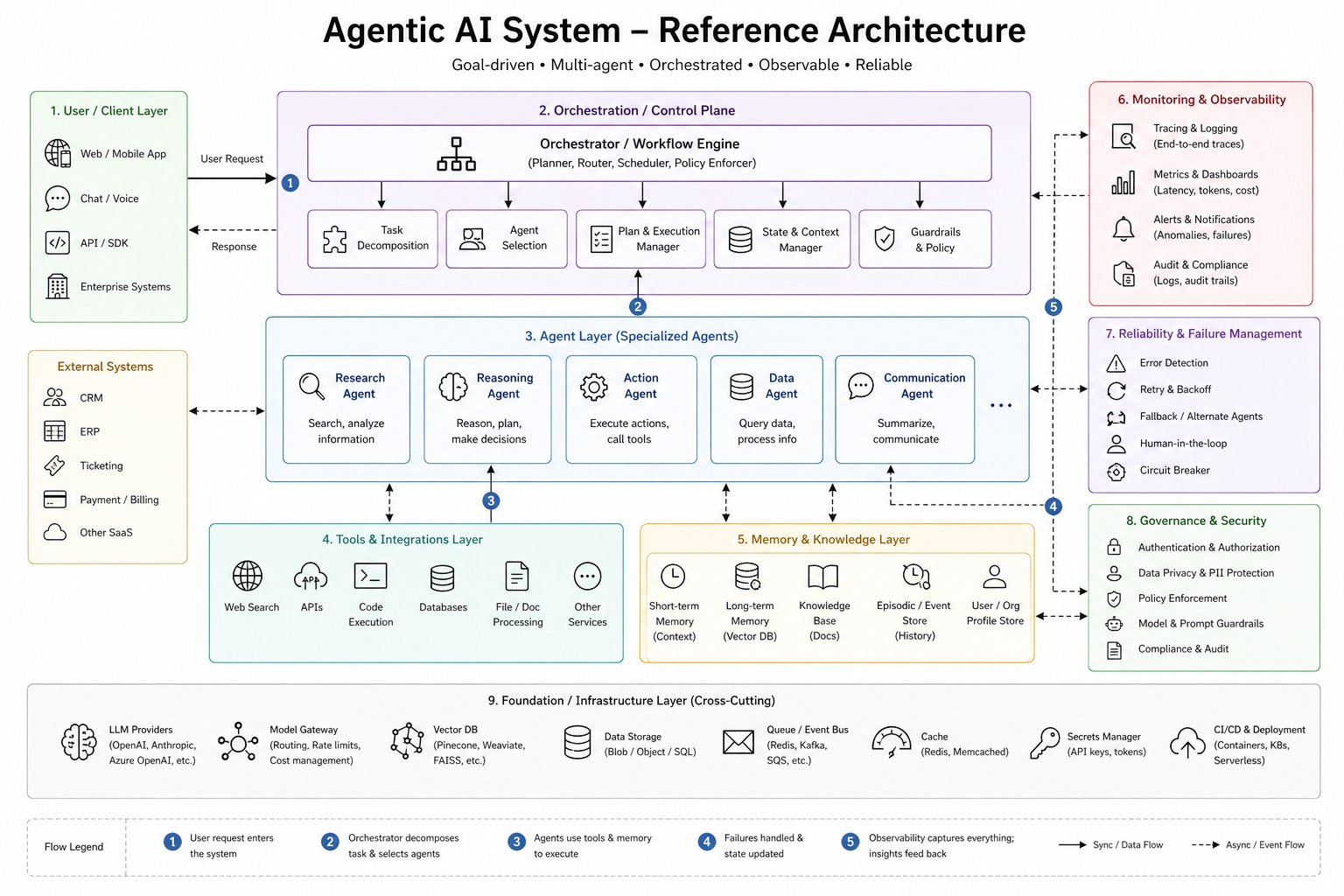
If you have spent any of the last eighteen months shipping LLM features into production, you already know the joke. The demo works. The pilot works. The first paying customer works. Then somewhere between the third tenant and the second region, the thing falls over in a way nobody on the team has ever seen before. The model is fine. The prompt is fine. What is not fine is that nobody drew the architecture.
This post is about the architecture. Specifically, the nine-layer reference model above, which has quietly become the default skeleton of every serious agentic system shipped in 2025 and 2026. We will walk it layer by layer, name the dominant tools at each one as of May 2026, call out the parts that are still unsettled, and close with a brief look at where the field is heading next.
Credit where credit is due: the diagram above is by Neha Sharma, originally posted on X. We have not changed a box. What follows is a long-form read of it, with citations to the primary sources at every load-bearing claim.
Why a reference architecture, now
Two years ago, you could build a respectable LLM product as a single prompt and a Stripe integration. The model did the reasoning, your application handled the rest, and the architecture diagram fit on a sticky note. That world ended around the time agents started calling tools, holding state across sessions, and routing requests between specialised models.
The transition broke a lot of teams. Not because the underlying technology got harder, but because the failure modes multiplied. A monolithic prompt has one way to be wrong. An orchestrator with five agents, twelve tools, three memory stores, and a guardrail layer has somewhere north of a thousand. Most of the post-mortems from 2024 and 2025 read the same way: a thing got bolted on, the bolted-on thing failed silently, the team had no instrumentation to see it, the failure compounded across a loop, and a customer noticed before the dashboard did.
A reference architecture is the answer that survived. Not because it prescribes the right tool at every layer, but because it forces the question. If you cannot point at the box in the diagram that handles a given concern, you have not handled it; you have hoped. The nine-layer model is descriptive first (every production system has these concerns whether you draw them or not) and prescriptive only by implication.
The rest of this post takes each layer in turn, names what is in it today, and flags what is changing. We are deliberately opinionated about the 2026 state of the art, and unapologetically conservative about which parts are settled.
Layer 1: User and client
The top layer is the surface area where requests originate and responses are delivered. It looks deceptively boring on the diagram, but it is the layer where most production complexity actually lives, because every other layer's failure mode eventually has to be expressed in something a user can see.
The 2026 surface set is wider than the 2024 one. Web and mobile chat are still the default, but voice has become mainstream through realtime APIs (OpenAI's Realtime API and Anthropic's streaming endpoints), and a generation of agentic products are now API-first, with the human interface being a thin shell over a richer machine-to-machine surface. Vercel AI SDK 5 and AssistantUI made streaming UIs and generative interfaces a commodity; the question is no longer 'can we stream tool calls into the UI' but 'should we, given the cognitive load on the user'.
The architectural decision at this layer is mostly about backpressure and grounding. Backpressure, because users will issue a second request before the first one has finished, and your client needs to decide whether to queue, cancel, or merge. Grounding, because the surface is the only place an agent can ask the user a clarifying question before burning fifteen tool calls down the wrong path. Teams that skipped human-in-the-loop primitives at this layer in 2024 spent most of 2025 retrofitting them.
Enterprise integrations (the CRM, ERP, and ticketing surfaces in the diagram's external systems column) belong at this layer too, conceptually, even though they look more like tools. The distinction is direction: they are the surfaces from which a request originates, not the ones an agent reaches into. A Salesforce flow that triggers an agent is a client; a Salesforce record an agent updates is a tool. The same vendor can be both, and getting that wrong is one of the more common architectural mistakes in 2026 deployments.
Layer 2: Orchestration and control plane
This is the layer that does not exist in your prototype and absolutely must exist in your production system. Its four jobs in the diagram (planner, router, scheduler, policy enforcer) are not optional. They are roles your code will play whether you architect them or not. The only choice is whether they live in one place where you can reason about them, or scattered across the codebase where they cannot be debugged.
The orchestration framework landscape settled noticeably in 2025 and now looks roughly like this:
- LangGraph reached 1.0 GA and is the default for teams who want graph-shaped orchestration where every node is a function and every edge is explicit. The April 2026 release added type-safe streaming via
version="v2"returning unifiedStreamPartchunks, plus per-nodetimeoutarguments and aDeltaChannelthat stores incremental message-list deltas instead of full snapshots, which is a meaningful cost saver for long threads. - CrewAI crossed forty-five thousand GitHub stars and is the default for role-shaped orchestration: declare a crew of agents with goals and backstories, choose a process type (sequential, hierarchical, consensual), and let the framework wire it up. Hierarchical mode now auto-assigns a manager agent that delegates and validates outputs.
- AutoGen v0.4 reimagined the project around an asynchronous, event-driven core, but Microsoft has confirmed AutoGen is now in maintenance mode, with no new features and a community-managed future. It remains a credible reference architecture for event-driven multi-agent systems; it is not the safe default it used to be.
- OpenAI's Agents SDK received a substantial April 2026 update with native sandbox execution (Blaxel, Cloudflare, Daytona, E2B, Modal, Runloop, Vercel as built-in providers) and a model-native harness that supports snapshot and rehydration so an agent can resume from a checkpoint in a fresh container.
- Pydantic AI continues as the choice for teams who want type safety as a first-class architectural concern; v1.91.0 is the May 2026 release.
Anthropic's Building Effective Agents paper still defines the canonical patterns: prompt chaining, routing, parallelisation (sectioning and voting), orchestrator-workers, and evaluator-optimiser, with the autonomous-agent loop as the upper bound. The right pattern is almost always the simplest one that solves your problem, and most teams that reach for orchestrator-workers should have stayed with routing. Andrew Ng's four-pattern shorthand (reflection, tool use, planning, multi-agent collaboration) is a useful mnemonic when explaining the layer to non-technical stakeholders, but the Anthropic paper is what you reach for at design time.
Layer 3: Specialised agents
The five-agent typology in the diagram (research, reasoning, action, data, communication) is not a strict ontology so much as a useful starting set. Most production systems collapse two or more of these into one agent and add one or two specific to their domain. The taxonomic question matters less than the architectural one: when do you split an agent at all?
Anthropic's multi-agent research system engineering post is the empirical reference. Their headline result was that a Claude Opus 4 lead agent coordinating Sonnet 4 subagents outperformed single-agent Claude Opus 4 by 90.2% on their internal research evaluation. The catch, and it is a meaningful one, is that the multi-agent system used roughly fifteen times the tokens of a single chat. A single agent uses about four times. The economics only work when the task is high-value, and the gain shows up most strongly on breadth-first queries (their example was 'all board members across S&P 500 IT firms'), where parallelism converts wall-clock time into throughput.
The practical heuristic, distilled from a year of reading multi-agent post-mortems: split an agent when the prompts disagree. If the policy you want a research agent to follow ('be thorough, follow every promising lead, do not stop until you have triangulated') actively contradicts the policy you want an action agent to follow ('be conservative, confirm before destructive operations, prefer the smallest reversible change'), you have two agents. If the only difference between two prompts is the tools they have access to, you have one agent and a router.
The other split worth making, even at the prototype stage, is between agents that plan and agents that act. Planning agents keep state across the loop; acting agents are usually stateless. Mixing the two roles is the single most common cause of agents that get stuck in loops nobody can debug, because the policy that should suppress retries lives in the same context window as the policy that drives them.
Layer 4: Tools and integrations
If 2024 was the year of the function call, 2025 was the year of MCP. The Model Context Protocol started 2025 with around twelve hundred public servers; it ended the year with somewhere between sixty-eight hundred (DigitalApplied's curated count) and seventeen thousand (Nerq's permissive census), depending on how strictly you count. By April 2026 the curated count was over ninety-four hundred and the registry was still adding eighteen percent month over month. Seventy-eight percent of enterprise AI teams now report at least one MCP-backed agent in production. The protocol has won.
What this means architecturally is that the integration boundary in your system has migrated. Two years ago, 'tools' meant function definitions inside a single application's prompt. Today, tools are independently versioned, independently authored, independently authenticated services that any agent can discover. The official MCP Registry at registry.modelcontextprotocol.io hit v0.1 API freeze in October 2025 and is now the root of trust most enterprises mirror with their own allow and deny lists. Smithery, PulseMCP, and mcp.so are the dominant marketplaces. Claude (native), ChatGPT (via the Apps SDK and Connectors), and Google Gemini (via Vertex AI Agent Builder, March 2026) all support MCP natively.
Tool design itself has not changed much. The principles that mattered in 2023 still matter: idempotency, schema clarity, deterministic error contracts, and a cost surface (tokens or money) that the agent can see. What has changed is that you almost certainly should not be authoring most of these from scratch. If your tool calls a SaaS your customers also use, there is a high probability someone has already written and published a tested MCP server for it. Audit it for security and ship.
Code execution sandboxes are the one tool category worth singling out. Anthropic's code-execution tool, E2B, Daytona, Modal, and Cloudflare Workers AI all converged in 2025 on a similar primitive: a container the agent can run arbitrary code in, scoped to the session, with mounted state. OpenAI's Agents SDK update in April 2026 made this a first-class feature with snapshot-and-rehydrate semantics. If your agent reasons about anything quantitative, have it write Python instead of doing the maths in tokens. The accuracy and cost both improve.
Layer 5: Memory and knowledge
The memory layer has more vendors and less consensus than any other layer in the diagram. There are five canonical memory types (short-term, long-term, knowledge base, episodic, profile), each with a different optimal substrate, and the marketplace has fragmented along those lines rather than consolidated.
- Short-term memory is the model's context window. Anthropic's prompt caching (1.25x base input price for the five-minute write, 0.10x for reads; 2x for the hour-long write) and agentic search are the primitives that matter. If you are loading the same hundred kilobytes of system prompt on every turn without caching, you are paying for it.
- Long-term memory is whatever your vector store is. Pinecone, Weaviate, Qdrant, FAISS, and pgvector all coexist; the choice is mostly operational rather than functional.
- Knowledge base is your RAG layer. The shape it should take depends on whether your knowledge is stable (in which case build it once, embed it, query it cheaply) or volatile (in which case embedding is the wrong primitive and you want agentic search).
- Episodic memory is conversation history. Storage is trivial; what is hard is summarisation policy, because the alternative to storage is rolling summarisation and that is where most teams either lose information or pay too much for it.
- Profile memory is everything you know about the user that should persist across sessions.
Anthropic's two memory primitives released in 2025 and 2026 are worth knowing well. The client-side memory tool (September 2025 beta) is a structured tool the model calls against a /memory directory you control. The server-side persistent memory feature on Managed Agents (April 2026 public beta) takes that further: each workspace has a /mnt/memory/ mount inside the agent container, and the agent reads and writes through the same bash and file tools it already has. Reported customer outcomes from Netflix, Rakuten, Wisedocs, and Ando cited a ninety-seven percent reduction in first-pass errors and a thirty percent speed increase on document-verification workflows.
The dedicated memory-framework category has consolidated to four credible options: Mem0 extracts and updates memories from interactions rather than appending them; Letta (formerly MemGPT) treats the LLM as an OS managing main, recall, and archival stores via function calls; Zep is a temporal knowledge graph powered by open-source Graphiti where every fact has a validity window and gets superseded rather than overwritten; Cognee is knowledge-graph-first via its ECL pipeline (extract, cognify, load). The choice is largely about how much of the memory policy you want to own. Mem0 gives you the most leverage; Letta gives you the most control; Zep gives you the most temporal correctness; Cognee gives you the most graph structure.
Layer 6: Monitoring and observability
The single biggest difference between a production agentic system and a prototype is not the model or the orchestration. It is whether you can see what the system is doing, in real time, with sufficient granularity to debug a failed loop after the fact. In 2024 most teams realised this only after their first outage. By 2026 the question 'which observability platform do you use' is roughly as standard at architecture interviews as 'which database'.
The vendor landscape sorts cleanly:
- LangSmith is the LangChain-native option. Deepest integration if your stack is already LangChain or LangGraph; node-by-node state diffs, full agent execution graphs, tool-call breakdowns, replay against new model versions. Cloud-only with a VPC enterprise tier. Setup is roughly fifteen minutes for a LangChain stack.
- Langfuse is the open-source self-host leader, Postgres plus ClickHouse. At fifty million spans per month, Langfuse Cloud runs about thirty-six thousand dollars a year before retention overage; the self-host version is free if you can operate it.
- Arize Phoenix brings ML-grade evaluation rigour and is open-source self-host; the Arize cloud tier is enterprise priced.
- Helicone is the simplest install (proxy URL change, five minutes) but entered maintenance mode in 2026; existing customers should plan a six- to twelve-month migration.
- Datadog and Honeycomb are the enterprise-default and event-based-deep-trace options respectively, both with native LLM observability features that arrived in 2025.
The OpenTelemetry GenAI semantic conventions are the longer-term answer. Most attributes are still marked experimental as of March 2026, but Datadog added native support in OTel v1.37, Grafana now collects LLM traces in Loki, and the Elastic 2026 observability survey reported that eighty-five percent of organisations already use some form of GenAI observability with a projected ninety-eight percent within two years. If you are building today, instrumenting against the GenAI conventions (with the OTEL_SEMCONV_STABILITY_OPT_IN shim for legacy attribute names) is the bet that survives a vendor change.
What to measure is a separate question. Token cost per task, tool-call latency, agent loop length, and end-to-end success rate are the four numbers every dashboard should have. Without them, your post-mortems read 'something went wrong somewhere'. With them, they read 'tool X returned a 504 on attempt three of seven, the agent retried with the same payload, and the loop terminated when it hit the max-step ceiling'. One of these is debuggable.
Layer 7: Reliability and failure management
Reliability for agents is not a port of reliability for microservices, although the patterns rhyme. Retry with exponential backoff, fallback chains, and circuit breakers (the Hystrix patterns of the 2010s) all transfer cleanly. What does not transfer is the assumption that a retry is cheap. Each LLM retry costs tokens; each tool call may have side effects; each loop iteration consumes context window that you cannot get back. The patterns survive but the cost model changes.
The practical defence in depth most production systems converge on:
- Bounded loops. Every agentic loop has an explicit max-step ceiling. The right number depends on the task; the right behaviour at the ceiling is to surface to a human, not to fail silently.
- Fallback chains. If the primary model is rate-limited or unavailable, route to a secondary. Most teams underinvest here until their first multi-hour incident, after which they overinvest. The middle ground is a model gateway (Portkey, OpenRouter, LiteLLM) that handles this declaratively.
- Semantic loop detection. A loop where the agent calls the same tool with the same arguments three times in a row is almost always stuck. Detecting this pattern and breaking out of it programmatically saves a remarkable amount of money.
- Human-in-the-loop checkpoints. For destructive operations, irreversible operations, or operations with a financial cost above a threshold, the right policy is to confirm with a human. The 2026 best practice is a typed approval primitive that the orchestrator handles, not an ad-hoc Slack message.
- Snapshot and rehydrate. OpenAI's Agents SDK harness made this a first-class feature in April 2026, and we expect it to become the default across frameworks within a year. An agent that can resume from a checkpoint in a fresh container is one that can survive the failure modes of long-running tasks.
The failure mode worth singling out is the stuck loop. A 2025 incident analysis at one of the larger AI labs (referenced in their internal post-mortems) found that more than half of long-running agent failures were not crashes but loops where the agent kept making technically-valid tool calls that did not advance the goal. The mitigation is mechanical: cap step counts, cap wall-clock time, detect repetition, and surface to a human at the boundary.
Layer 8: Governance and security
Prompt injection has been number one on the OWASP LLM Top 10 for three consecutive years, and 2026 is no exception. The reason is structural: a system that ingests untrusted text and lets a language model take action on it has, definitionally, an injection surface. The defences are not perfect but they have matured.
The layered defence stack that has converged in production:
- Structured prompt formatting. System prompts get the policy; user inputs are clearly tagged; tool outputs are tagged separately. This does not stop injection but it raises the cost.
- Output schema validation. If the agent's output must conform to a schema, an injected instruction that produces freeform text fails fast. Pydantic AI and the OpenAI Structured Outputs feature are the obvious tools.
- Rate limiting and reputation. Most prompt injections come in volumes; rate limits and reputation systems catch a meaningful fraction.
- LLM-based filtering. Anthropic's Constitutional Classifiers (research, January 2025) reduced jailbreak success from 86% to 4.4% at a cost of 23.7% additional compute and 0.38% added refusal rate on harmless queries. The next-generation classifiers (a two-stage architecture with a lightweight probe and a heavier escalation classifier) cut compute overhead by 40x while maintaining a 0.05% production refusal rate.
- Open guardrail models. Llama Guard, NVIDIA NeMo Guardrails (v0.20.0 as of January 2026, with native LangGraph integration), ShieldGemma, IBM Granite Guardian, and Prompt Guard cover the open-source side. Layered with Anthropic Constitutional Classifiers or equivalent commercial guardrails, the residual risk on well-architected systems is manageable.
Incidents matter for calibration. The Air Canada bereavement-fare ruling held the airline liable for what its chatbot said. The 2025 zero-click attack on AI-powered IDEs used a Google Doc to trigger an agent into fetching attacker instructions from an MCP server. GitHub Copilot's CVE-2025-53773 was a remote code execution; CamoLeak was scored CVSS 9.6. The category is not theoretical.
The regulatory picture sharpened in 2025 and 2026. The EU AI Act's GPAI obligations applied from 2 August 2025; the Commission's enforcement powers do not enter application until 2 August 2026, so as of this post providers are obligated but not yet enforced against. The GPAI Code of Practice is the demonstrated-compliance pathway and signatories' adherence will be a mitigating factor in fine determinations. On 7 May 2026, the Council and Parliament reached provisional agreement on simplifying the rules and clarifying that the AI Office has competence over GPAI-derived systems where the model and system share a provider. Whatever your jurisdiction, the model from now on is conformity-by-design rather than retrofit.
Layer 9: Foundation and infrastructure
The bottom layer of the diagram is the cross-cutting infrastructure that everything above it sits on: LLM providers, model gateways, vector databases, queues, caches, secrets, and CI/CD. This is the layer that is least specific to agentic systems and most specific to your operating environment, but two trends are worth naming.
First, model gateways are no longer optional. Portkey, OpenRouter, LiteLLM, and the major cloud providers' equivalents (Bedrock, Vertex, Azure AI Foundry) all provide a uniform interface across providers, route by cost or latency or capability, and handle fallback chains, rate limits, and request-level cost attribution. If you have more than one provider in your stack, or expect to within twelve months, the gateway saves you a meaningful refactor later. If you have only one, it adds a small operational tax but very low integration cost; we put it in by default.
Second, the agent stack has become the new web stack. The shape is recognisable: a framework (LangGraph, CrewAI, the OpenAI Agents SDK), a deployment runtime (Vercel, Cloudflare, Modal, Anthropic Managed Agents, OpenAI's hosted Agents), an observability platform, a model gateway, a memory store, and a CI/CD pipeline that runs evals as well as tests. None of these are new categories. What is new is that they finally exist as discrete, swappable products rather than as parts of monolithic platforms. The default architecture for a 2026 greenfield build is a stack of seven to ten of these, chosen on operational grounds.
The one piece of infrastructure that is genuinely new and worth understanding is the agent runtime. Anthropic Managed Agents (with the workspace-scoped /mnt/memory/ mount), OpenAI's hosted Agents SDK with its sandbox-and-rehydrate harness, and Cloudflare Workers AI with its Durable Objects all converge on the same idea: an isolated container with mounted state that the agent owns for the duration of a session, billed at standard token rates plus a per-hour runtime fee (Anthropic's number is eight cents per session-hour). This is the production-grade replacement for the prototype pattern of running agents in your own application server, and it changes the operating cost model.
State of the art, Q2 2026
Three shifts since the start of 2026 are worth flagging for anyone still calibrating their architectural defaults.
Long-running autonomous agents are no longer a research demo. Claude Sonnet 4.5 was reported running thirty-plus hours of autonomous focus on multi-step coding tasks. A specific Anthropic case study cited in the 2026 Agentic Coding Trends Report documented a seven-hour single autonomous run by Claude Code on the vLLM library (twelve-and-a-half million lines), extracting an activation vector at 99.9% numerical accuracy versus the reference. Anthropic's Claude Code Auto Mode, covered by InfoQ in May 2026, formalised the integration model: autonomous coding loops with explicit human approval gates as the boundary primitive. The implication for architecture is that the bounded-loop assumption (max steps in low double digits, max wall-clock in tens of minutes) is now wrong by an order of magnitude for high-capability tasks.
Claude Skills became the default agent runtime primitive. Skills launched as skills-2025-10-02 beta and became open standard in late 2025, with a SKILL.md file containing YAML frontmatter (name, description, optional allowed-tools) plus markdown instructions. The runtime model is progressive disclosure: at session start the model scans only the name and description (around a hundred tokens per skill), and the full body (target under five thousand tokens, recommended under five hundred lines) loads only when triggered. Anthropic shipped managed Skills for PowerPoint, Excel, Word, and PDF; Canva, Notion, Figma, and Atlassian shipped prebuilt partner Skills; org-wide Skill management arrived for Team and Enterprise. The pricing model on Managed Agents is standard token rates plus eight cents per session-hour of active runtime.
Benchmarks have moved on from HumanEval. HumanEval saturated; frontier models all score above 95% and the problems have been public since 2021. The contamination-resistant successors are LiveCodeBench (continuously sourced from LeetCode, AtCoder, CodeForces post-cutoff), SWE-bench Verified for production-relevant coding (where Claude Mythos Preview leads at 93.9% as of May 2026, GPT-5.5 at 88.7%, Claude Opus 4.7 at 87.6%), GAIA for agentic research (Claude Sonnet 4.5 leads scaffolded at 74.6%), tau2-bench for policy-adherence (Claude Sonnet 4.5 at 0.862 retail, 0.700 airline), and Humanity's Last Exam for frontier-knowledge questions (Claude Mythos Preview at 64.7%). The takeaway: cite leaderboards, not numbers in isolation, because the gap between bare-model and scaffolded-agent scores has become wide enough that 'state of the art' depends on whether you mean the model or the system.
Art of the possible
The research front is moving faster than the production stack, which means the architecture you ship in 2026 needs to be able to absorb a small number of genuinely new primitives without a rewrite. Four are worth tracking.
Persistent agents with multi-month memory. Anthropic's server-side memory tool (April 2026 public beta) is the production-shipped version of an idea that academic work has been chasing for two years. The implication is that 'state' is no longer something the orchestrator owns; the agent owns it. The architectural change is subtle but real. If your design assumes the orchestrator is the source of truth for 'what has happened in this session', you are about to be wrong.
Self-improving agent loops. Meta's HyperAgents (arXiv 2603.19461, March 2026) introduced self-referential agents that integrate a task agent and a meta agent into a single editable program, where the meta-level modification procedure is itself editable. Self-Improving AI Agents through Self-Play (arXiv 2512.02731) unifies AlphaZero, GANs, STaR, SPIN, RLHF, Constitutional AI, Self-Instruct, and GRPO under a single GVU operator. The ICLR 2026 Lifelong Agent workshop accepted A Systematic Survey of Self-Evolving Agents: From Model-Centric to Environment-Driven Co-Evolution. These are research, not products, but the production implication is that within twelve to twenty-four months you will see agents that change their own prompts, tool selections, and routing policies in response to evaluation feedback. The architectural ask is that your evaluation harness is good enough to be the safety boundary on that.
Agent and MCP marketplaces. Smithery, PulseMCP, mcp.so, the official MCP Registry, the Claude Skills marketplace, GPT Store, Hugging Face Spaces, Replit Agent Market, LangChain Hub, Vercel Agent Gallery, and Cloudflare AI Marketplace are all live. We are at the discovery-and-distribution stage; the trust stage (cryptographic attestation, runtime sandboxing, supply-chain audit) is still maturing. If your architecture assumes you control every MCP server in your stack, plan for the day you do not.
Formal verification of agents. The ICLR 2026 Workshop on Agents in the Wild featured Formalising the Safety, Security, and Functional Properties of Agentic AI Systems (arXiv 2510.14133); AgentGuard: Runtime Verification of AI Agents (arXiv 2509.23864) introduced the term Dynamic Probabilistic Assurance; Saarthi: The First AI Formal Verification Engineer (arXiv 2502.16662) demonstrated an agentic workflow that does verification planning, generates SystemVerilog assertions, proves properties, and analyses counterexamples. Formal methods for agent systems are not yet table stakes. They will be, on a roughly five-year horizon, for any agent that touches a regulated workflow.
How ClawCert embodies this architecture
We will not pretend this is an academic exercise for us. ClawCert is itself an agentic system, and the nine-layer model maps onto it cleanly enough that we use it internally as the diagram on the wall.
- Orchestration is a four-factor planner in
apps/api/app/services/adaptive_sequencer.pythat selects the next knowledge point each session, weighing prerequisite readiness, weakness signals, domain priority, and spaced-repetition schedule. Bayesian Knowledge Tracing inapps/api/app/services/bkt_engine.pyis the state model the planner queries. - Agents. Archie, our Socratic tutor, is a reasoning agent (
tutor_service.py) constrained by an output guardrail it never violates: never give the answer. The BKT engine acts as a state agent. The SM-2 spaced-repetition scheduler is an action agent. - Memory. Long-term memory is the
learner_kp_statetable in PostgreSQL (one row per learner per knowledge point, holding mastery probability, SM-2 interval, and review schedule). Episodic memory is the conversation history per session. The knowledge base is the YAML knowledge graph indata/knowledge_graph/, loaded into Postgres at runtime, with the YAML as the source of truth. - Observability. Token tracking lives in
apps/api/app/services/token_tracker.py; per-session response logs cover the loop length and outcome metrics. The eval harness is the question bank indata/question_bank/, used both for delivery and for offline evaluation of tutor performance. - Governance. The 'never give the answer' constraint is the load-bearing output guardrail; misconception detection in the tutor classifies wrong reasoning patterns and feeds them back into the BKT model rather than treating them as opaque incorrectness.
The shape of the system is recognisable. The point of this section is not to claim novelty for ClawCert; it is to demonstrate that the reference architecture is descriptive enough to fit a single-tenant educational system as cleanly as it fits an enterprise contact centre.
Mapping to the Claude Certified Architect exam
If you are studying for the Foundations exam, the layer-to-domain mapping below is the version we use internally. The percentages are the official domain weights; the layer references are the sections of this post.
| Layer | Closest exam domain | Weight |
|---|---|---|
| 2: Orchestration and control plane | Domain 1 (Agentic Architecture and Orchestration) | 27% |
| 3: Specialised agents | Domain 1 (subagent isolation and multi-agent patterns) | 27% |
| 4: Tools and integrations | Domain 2 (Tool Design and MCP Integration) | 18% |
| 5: Memory and knowledge | Domain 5 (Context Management and Reliability) | 15% |
| 6: Observability and evaluation | Domain 4 (Prompt Engineering and Structured Output, eval portion) | 20% |
| 7: Reliability and failure management | Domain 5 (Reliability and Recovery) | 15% |
| 8: Governance and security | cross-cutting; partial Domain 4 | n/a |
| 9: Foundation and infrastructure | Domain 3 (Claude Code Configuration and Workflows) | 20% |
Domains 1 and 3 are where most candidates lose points, in our internal data; the agentic loop and the configuration surface together account for nearly half the question bank. If you are prioritising study time, Layer 2 and Layer 9 in this post are the load-bearing sections.
Where to go next
If you read one thing after this post, make it Anthropic's Building Effective Agents. If you read two, add the multi-agent research system engineering post. Together they are the primary sources behind most of the architectural choices we have argued for above, and most of the production patterns that have stabilised in 2025 and 2026.
If you are building, the question that survives all nine layers is the same one: which box owns this concern, and where can I read its logs at three in the morning. Architectures live or die on that answer.
If you are studying for the Claude Certified Architect exam, this post is roughly the architecture-shaped version of the syllabus; the next-best step is to start a study session and let the engine pick the layer you are weakest on.
About the author
AI Architect & Certification Lead
Solomon Udoh is an AI Architect who designs and ships production agent systems on the Claude API and Claude Code. He built AI Skill Certs' adaptive engine and authored its 174-concept knowledge graph, mapping every Claude Certified Architect - Foundations objective to hands-on, exam-aligned practice.
- Designs production multi-agent systems on the Claude API and Agent SDK
- Author of the AI Skill Certs knowledge graph (174 mapped exam concepts)
- Builds with MCP, Claude Code, structured outputs, and agentic loops daily
- Reviews every concept page against the official Anthropic exam guide
You might also like
Ready to put it into practice?
Study every exam concept with an adaptive tutor.